GradioでHugging Face Datasetをオフライン表示する
要約
- Hugging Face公式の Dataset Viewer は重く、表示されないことが多い
gradio+datasetsライブラリを使えば、ローカルキャッシュのみを使った高速ビューアがPythonだけで作れる- 音声(
.wav/.flac)・画像のインライン再生・表示にも対応 - スクリプト1本(約300行)でページネーション、Streaming対応まで完備
- 筆者は話者分離・音声認識(ASR)の学習データ確認用として実際に使用中
はじめに:Hugging Face Dataset Viewerへの不満
機械学習のデータセットを扱っていると、Hugging Faceのウェブ上の Dataset Viewer をよく使います。しかし、実際の現場では以下の問題が頻発します。
- 重い:大規模データセット(例:
reazon-research/reazonspeech)では数秒〜数十秒待つことも - 表示されない:「Dataset preview is not available」と出て何も見えない
- 音声が聴けない:ブラウザでの再生が制限されていることがある
特に、話者分離(Speaker Diarization)や音声認識(ASR: Automatic Speech Recognition)のような音声データを大量に扱う研究・開発現場では、データの中身を素早く確認したいケースが多く、このストレスは深刻です。
そこで筆者は、ローカルにキャッシュ済みのデータだけを使って動く自作ビューアを作ることにしました。
使った技術スタック
| ライブラリ | 用途 |
|---|---|
gradio | Web UIの構築(Python只で完結) |
datasets | Hugging Faceデータセットの読み込み |
mimetypes | 音声・画像ファイルのMIMEタイプ推定 |
base64 | メディアファイルのインラインHTML埋め込み |
Gradioとは?
**Gradio(グラディオ)**はPython用のWebUIライブラリです。FastAPIやFlaskのような低レイヤーな設定なしに、スライダー・テキストボックス・ボタン・HTML表示などのUIを数行で作れます。機械学習のデモや社内ツールに向いており、pip install gradioだけで使い始められます。
実装のポイントと設計思想
1. Streamingモードとの両立
Hugging FaceのDatasetには、ダウンロードせず少しずつ読み込む Streamingモード があります。巨大なデータセットに有効ですが、len()が使えなかったり、ランダムアクセスが難しい制約があります。
本ビューアでは streaming フラグを明示的に分離し、どちらでも動くように設計しました。
dataset = load_dataset(
repo_id,
name=config or None,
split=split,
streaming=streaming, # Trueならイテラブル、FalseならDataset
trust_remote_code=trust_remote_code,
)
2. 音声・画像のdecode=Falseが肝
datasetsライブラリはデフォルトで音声や画像を自動デコードします。しかし、ブラウザ表示には生バイト列やファイルパスの方が都合がよい。そのため、decode=Falseでデコードを止め、base64エンコードしてHTMLに埋め込みます。
for column, feature in _feature_items(features):
if isinstance(feature, Audio):
dataset = dataset.cast_column(column, Audio(decode=False))
if isinstance(feature, Image):
dataset = dataset.cast_column(column, Image(decode=False))
これにより、音声列は {"bytes": b"...", "path": "sample.wav"} という辞書形式で返ってくるため、そのままbase64変換してHTMLの<audio>タグに渡せます。
def _audio_player_html(value, *, player_id):
audio_src = _media_src(value, media_kind="audio")
mime_type = _media_mime(value, media_kind="audio")
return (
f'<audio id="{player_id}" controls preload="none" '
f'style="width:220px;" src="{audio_src}" type="{mime_type}"></audio>'
)
3. ページネーションの実装
Streamingデータセットはオフセットアクセス(dataset[10:20])ができないため、先頭から逐次イテレートして目的の範囲だけ取り出しています。
def materialize_page(dataset, *, offset, limit):
rows = []
for index, sample in enumerate(iter(dataset)):
if index < offset:
continue
if len(rows) >= limit:
break
rows.append({"row_index": index, "sample": sample})
return rows
大きなoffsetでは遅くなりますが、ローカルキャッシュからの読み込みなら実用的な速度です。
4. MIMEタイプの自動推定
ファイル拡張子からmimetypes.guess_type()でMIMEタイプを推定し、.flacならaudio/flac、.wavならaudio/wav、.pngならimage/pngを自動で割り当てます。推定できない場合はデフォルト値にフォールバックします。
def _guess_mime(path, *, media_kind):
suffix = Path(path or "").suffix.lower()
guessed, _ = mimetypes.guess_type(f"dummy{suffix}")
if guessed:
return guessed
return "image/png" if media_kind == "image" else "audio/wav"
完全なコード
from __future__ import annotations
import argparse
import base64
import html
import json
import mimetypes
from pathlib import Path
from typing import Any
import gradio as gr
from datasets import (
Audio, Dataset, Features, Image, IterableDataset,
get_dataset_config_names, get_dataset_split_names, load_dataset,
)
DEFAULT_REPO_ID = "reazon-research/reazonspeech"
DEFAULT_CONFIG = "tiny"
DEFAULT_SPLIT = "train"
def load_hf_dataset(*, repo_id, config, split, streaming, trust_remote_code):
dataset = load_dataset(
repo_id, name=config or None, split=split,
streaming=streaming, trust_remote_code=trust_remote_code,
)
features = getattr(dataset, "features", {})
for column, feature in _feature_items(features):
if isinstance(feature, Audio):
dataset = dataset.cast_column(column, Audio(decode=False))
if isinstance(feature, Image):
dataset = dataset.cast_column(column, Image(decode=False))
return dataset
def materialize_page(dataset, *, offset, limit):
rows = []
for index, sample in enumerate(_iter_dataset(dataset)):
if index < offset:
continue
if len(rows) >= limit:
break
rows.append({"row_index": index, "sample": sample})
return rows
def dataset_size(dataset):
try:
return len(dataset)
except TypeError:
return None
def infer_display_columns(rows):
if not rows:
return []
seen = []
for row in rows:
for key in row["sample"].keys():
if key not in seen:
seen.append(key)
return seen
def infer_media_columns(rows, features):
media_columns = {}
for column, feature in _feature_items(features):
if isinstance(feature, Audio):
media_columns[column] = "audio"
elif isinstance(feature, Image):
media_columns[column] = "image"
for row in rows:
for column, value in row["sample"].items():
if column in media_columns:
continue
guessed = _guess_media_kind(value)
if guessed:
media_columns[column] = guessed
return media_columns
def build_table_html(rows, *, render_token="", display_columns=None, media_columns=None):
display_columns = display_columns or infer_display_columns(rows)
media_columns = media_columns or {}
table_rows = []
for row in rows:
value_cells = []
for column in display_columns:
value = row["sample"].get(column)
kind = media_columns.get(column)
rendered_value = _render_cell_value(
value, kind=kind, cell_id=f"{render_token}-{row['row_index']}-{column}"
)
value_cells.append(
f'<td style="border-bottom:1px solid #eee; padding:8px; vertical-align:top;">'
f'{rendered_value}</td>'
)
table_rows.append(
"<tr>"
f'<td style="border-bottom:1px solid #eee; padding:8px;">{row["row_index"]}</td>'
+ "".join(value_cells) + "</tr>"
)
header_cells = ['<th style="width:80px; text-align:left; padding:8px;">row</th>']
for column in display_columns:
header_cells.append(f'<th style="text-align:left; padding:8px;">{html.escape(column)}</th>')
body = "".join(table_rows) or f'<tr><td colspan="{len(display_columns)+1}">No rows</td></tr>'
return f'<div style="overflow-x:auto;"><table style="width:100%; border-collapse:collapse;"><thead><tr>{"".join(header_cells)}</tr></thead><tbody>{body}</tbody></table></div>'
def inspect_dataset_info(repo_id, config, trust_remote_code):
repo_id = repo_id.strip()
if not repo_id:
return "repo_id is required"
try:
config_names = get_dataset_config_names(repo_id, trust_remote_code=trust_remote_code)
effective_config = config.strip() or (config_names[0] if config_names else None)
split_names = get_dataset_split_names(repo_id, config_name=effective_config, trust_remote_code=trust_remote_code)
config_text = ", ".join(config_names) if config_names else "(default only)"
split_text = ", ".join(split_names) if split_names else "(unknown)"
return f"configs: {config_text}\nsplits[{effective_config}]: {split_text}"
except Exception as exc:
return f"{type(exc).__name__}: {exc}"
def create_app(default_rows=50, default_repo_id=DEFAULT_REPO_ID, default_config=DEFAULT_CONFIG, default_split=DEFAULT_SPLIT):
with gr.Blocks(title="HF Dataset Viewer") as demo:
query_state = gr.State({})
offset_state = gr.State(0)
gr.Markdown("# Hugging Face Dataset Viewer\nローカルキャッシュからデータセットを確認するGradioビューア")
with gr.Row():
repo_id = gr.Textbox(value=default_repo_id, label="Dataset repo_id")
config = gr.Textbox(value=default_config, label="Config / name")
split = gr.Textbox(value=default_split, label="Split")
with gr.Row():
row_limit = gr.Slider(minimum=10, maximum=200, value=default_rows, step=10, label="Rows")
streaming = gr.Checkbox(value=False, label="Streaming")
trust_remote_code = gr.Checkbox(value=False, label="Trust remote code")
with gr.Row():
inspect_info = gr.Textbox(label="Dataset info", interactive=False, lines=3)
status = gr.Textbox(label="Status", interactive=False)
with gr.Row():
inspect_button = gr.Button("Inspect")
load_button = gr.Button("Load")
prev_button = gr.Button("Prev")
next_button = gr.Button("Next")
table = gr.HTML(value=build_table_html([], render_token="initial"))
def render_page(query, offset):
if not query:
return build_table_html([], render_token="empty"), 0, "No dataset loaded"
try:
dataset = load_hf_dataset(**{k: query[k] for k in ["repo_id","config","split","streaming","trust_remote_code"]})
rows = materialize_page(dataset, offset=max(0, int(offset)), limit=int(query["row_limit"]))
total_rows = dataset_size(dataset)
display_columns = infer_display_columns(rows)
media_columns = infer_media_columns(rows, getattr(dataset, "features", None))
render_token = f"{query['repo_id']}-{query['config']}-{query['split']}-{offset}"
table_html = build_table_html(rows, render_token=render_token, display_columns=display_columns, media_columns=media_columns)
if rows:
status_text = f"Showing rows {rows[0]['row_index']}-{rows[-1]['row_index']} (total: {total_rows})"
else:
status_text = f"No rows at offset {offset}"
return table_html, max(0, int(offset)), status_text
except Exception as exc:
return build_table_html([], render_token="error"), 0, f"{type(exc).__name__}: {exc}"
def load_rows(repo_id, config, split, row_limit, streaming, trust_remote_code):
query = {"repo_id": repo_id.strip(), "config": config.strip(), "split": split.strip(),
"row_limit": int(row_limit), "streaming": bool(streaming), "trust_remote_code": bool(trust_remote_code)}
table_html, offset, status_text = render_page(query, 0)
return query, offset, table_html, status_text
def change_page(direction, query, offset):
if not query:
return offset, build_table_html([], render_token="empty"), "No dataset loaded"
next_offset = max(0, int(offset) + direction * int(query["row_limit"]))
table_html, resolved_offset, status_text = render_page(query, next_offset)
if "No rows at offset" in status_text and next_offset > 0:
table_html, resolved_offset, status_text = render_page(query, offset)
return resolved_offset, table_html, status_text
inspect_button.click(inspect_dataset_info, inputs=[repo_id, config, trust_remote_code], outputs=[inspect_info])
load_button.click(load_rows, inputs=[repo_id, config, split, row_limit, streaming, trust_remote_code], outputs=[query_state, offset_state, table, status])
prev_button.click(lambda q, o: change_page(-1, q, o), inputs=[query_state, offset_state], outputs=[offset_state, table, status])
next_button.click(lambda q, o: change_page(1, q, o), inputs=[query_state, offset_state], outputs=[offset_state, table, status])
return demo
def _render_cell_value(value, *, kind, cell_id):
if value is None:
return ""
if kind == "audio":
return _audio_player_html(value, player_id=f"audio-{cell_id}")
if kind == "image":
return _image_html(value)
if isinstance(value, (dict, list, tuple)):
payload = json.dumps(value, ensure_ascii=True, default=str, indent=2)
return f"<pre style='margin:0; white-space:pre-wrap;'>{html.escape(payload)}</pre>"
if isinstance(value, bytes):
return html.escape(f"<{len(value)} bytes>")
return html.escape(str(value))
def _audio_player_html(value, *, player_id):
audio_src = _media_src(value, media_kind="audio")
if not audio_src:
return str(value)
mime_type = html.escape(_media_mime(value, media_kind="audio"), quote=True)
return f'<audio id="{html.escape(player_id)}" controls preload="none" style="width:220px;" src="{html.escape(audio_src)}" type="{mime_type}"></audio>'
def _image_html(value):
image_src = _media_src(value, media_kind="image")
if not image_src:
return str(value)
return f'<img alt="dataset image" src="{html.escape(image_src)}" style="max-width:220px; max-height:220px; object-fit:contain;" />'
def _media_src(value, *, media_kind):
if isinstance(value, dict):
media_bytes = value.get("bytes")
if media_bytes is not None:
mime_type = _media_mime(value, media_kind=media_kind)
encoded = base64.b64encode(media_bytes).decode("ascii")
return f"data:{mime_type};base64,{encoded}"
media_path = value.get("path")
if media_path:
return _file_to_browser_src(media_path, media_kind=media_kind)
if isinstance(value, str):
return _file_to_browser_src(value, media_kind=media_kind)
return None
def _media_mime(value, *, media_kind):
path = None
if isinstance(value, dict):
path = value.get("path")
elif isinstance(value, str):
path = value
return _guess_mime(path, media_kind=media_kind)
def _file_to_browser_src(path, *, media_kind):
try:
file_path = Path(path).expanduser().resolve()
if not file_path.exists():
return None
encoded = base64.b64encode(file_path.read_bytes()).decode("ascii")
return f"data:{_guess_mime(str(file_path), media_kind=media_kind)};base64,{encoded}"
except OSError:
return None
def _guess_mime(path, *, media_kind):
suffix = Path(path or "").suffix.lower()
guessed, _ = mimetypes.guess_type(f"dummy{suffix}")
if guessed:
return guessed
return "image/png" if media_kind == "image" else "audio/wav"
def _guess_media_kind(value):
path = None
if isinstance(value, dict):
path = value.get("path")
if value.get("bytes") is not None and path:
return _mime_to_media_kind(_guess_mime(path, media_kind="audio"))
elif isinstance(value, str):
path = value
if not path:
return None
guessed, _ = mimetypes.guess_type(path)
return _mime_to_media_kind(guessed)
def _mime_to_media_kind(mime_type):
if not mime_type:
return None
if mime_type.startswith("audio/"):
return "audio"
if mime_type.startswith("image/"):
return "image"
return None
def _feature_items(features):
if not features:
return []
if hasattr(features, "items"):
return list(features.items())
return []
def _iter_dataset(dataset):
return iter(dataset)
def main():
parser = argparse.ArgumentParser(description="HF dataset viewer")
parser.add_argument("--host", default="127.0.0.1")
parser.add_argument("--port", type=int, default=7860)
parser.add_argument("--rows", type=int, default=50)
parser.add_argument("--repo-id", default=DEFAULT_REPO_ID)
parser.add_argument("--config", default=DEFAULT_CONFIG)
parser.add_argument("--split", default=DEFAULT_SPLIT)
args = parser.parse_args()
demo = create_app(
default_rows=args.rows, default_repo_id=args.repo_id,
default_config=args.config, default_split=args.split,
)
demo.launch(server_name=args.host, server_port=args.port)
if __name__ == "__main__":
main()
セットアップと起動方法
pip install gradio datasets
# 起動(デフォルト)
python viewer.py
# カスタム設定で起動
python viewer.py \
--repo-id reazon-research/reazonspeech \
--config tiny \
--split train \
--rows 50 \
--port 7860
ブラウザで http://127.0.0.1:7860 を開けばUIが表示されます。
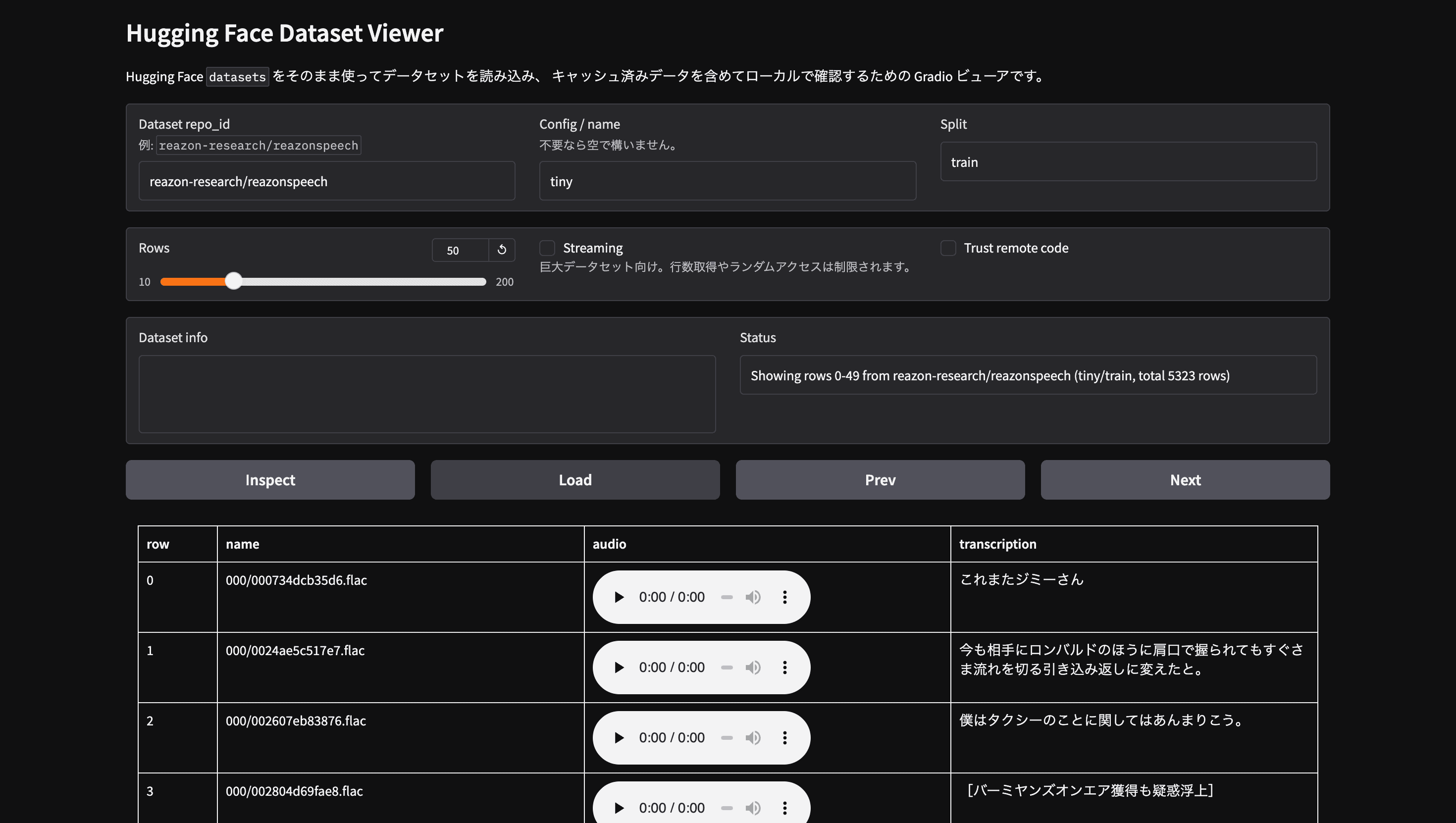
実際に使ってみた:ReazonSpeechでの動作確認
筆者は音声認識(ASR)モデルの評価・学習データ確認に reazon-research/reazonspeech(日本語音声コーパス)を使っています。このデータセットは音声列(audio)とテキスト列(transcription)を持ちます。
ReazonSpeechが公式Viewerから見えないので、ローカル環境でどんなデータセットか確認できました。
Repo、Config、Splitを変えれば基本的にどんなデータセットでもオフラインでローカル環境に表示できるよ。
特に恩恵を受けるユースケース
- **ASR(自動音声認識)**の学習データ品質確認
- **Speaker Diarization(話者分離)**のラベル確認
- **音声合成(TTS)**データセットの波形確認
- 画像分類データセットのラベルと画像の目視確認
工夫した点・ハマった点
preload="none" で重さを回避
<audio>タグにデフォルトでpreload="auto"を使うと、全行の音声が一度にロードされてブラウザがフリーズします。preload="none"にして、再生ボタンを押したときだけロードするようにしました。
decode=False を忘れると落ちる
cast_columnでdecode=Falseを指定しないと、datasetsライブラリが音声を自動でデコード(numpy配列化)してしまいます。numpy配列はHTMLに埋め込めないため、必ずデコードを止める必要があります。
Streamingオフセットは遅い
Streamingモードでページ100以降を表示しようとすると、最初の100サンプルを全てイテレートしてから取得するため遅くなります。ローカルにダウンロードしたデータセットはStreamingをオフにして使うのが推奨です。
今後の改善アイデア
- 列のフィルタ・ソート機能の追加
- テキスト検索(特定のtranscriptionを持つ行を検索)
- 統計情報の表示(音声長の分布など)
- Parquet直読み対応(
datasetsなしでも動くように)
FAQ
Q1. ネット接続なしでも動きますか?
A. はい。一度 datasets ライブラリでダウンロード・キャッシュされたデータセットは、load_datasetがオフラインでも~/.cache/huggingface/datasets/から読み込みます。ただし初回ダウンロードはネット接続が必要です。
Q2. 巨大なデータセット(数百GB)でも動きますか?
A. streaming=Trueにすれば、全データをメモリに載せずに動作します。ただし、大きなオフセットへのジャンプは遅くなります(先頭からイテレートするため)。
Q3. trust_remote_codeは安全ですか?
A. 信頼できるリポジトリ(公式・著名機関)のみで使用してください。trust_remote_code=Trueにすると、そのリポジトリのPythonコードがローカルで実行されます。デフォルトはFalseにしてあります。
Q4. Windows / Macでも動きますか?
A. 動作します。pathlib.Pathを使っているためOS依存はありません。ただしキャッシュパスはOSごとに異なります(WindowsはAppData配下など)。
Q5. Parquetファイルを直接読み込めますか?
A. 現状はdatasetsライブラリ経由のみ対応ですが、load_dataset("parquet", data_files="./data.parquet")の形式で指定すれば読み込めます。
Q6. 公式ビューアとの違いは何ですか?
A. 公式ビューアはサーバーサイドで動作し、常に最新データをHugging Faceから取得します。本ビューアはローカルキャッシュを直接参照するため、オフライン動作・高速表示が最大の利点です。一方、未ダウンロードのデータセットはロードできません。
Q7. Gradioのバージョン依存はありますか?
A. Gradio 4.x以上を推奨します。gr.Blocks、gr.State、gr.HTMLを使用しているため、古いバージョン(3.x以前)では動作しない可能性があります。
まとめ
| 課題 | 解決策 |
|---|---|
| 公式Viewerが重い・表示されない | ローカルキャッシュから直接読み込む |
| 音声の試聴ができない | base64エンコードで<audio>タグに埋め込む |
| 大規模データセットのメモリ問題 | Streamingモード対応 |
| UI開発の手間 | Gradioで最小コードで実現 |
Gradioは「機械学習デモ用」というイメージがありますが、このようなデータ確認ツールにも非常に向いています。PythonだけでWebUIが完結するので、データパイプラインのデバッグや学習データの品質確認ツールとして積極的に活用していきたいと思います。
スクリプト1本で完結するため、チームメンバーへの共有も python viewer.py だけで済みます。ぜひ試してみてください。
関連するブログ
この記事に近いテーマのブログをピックアップしています。
【2026年】話者分離モデル比較:NeMo SortFormer・VibeVoice・Pyannoteを実測
オープンソース話者分離モデル NeMo(SortFormer・MSDD)・VibeVoice ASR・Pyannoteを実音声で比較。DERスコアと用途別おすすめをまとめました。
記事を読む →【2026年版】IT用語に強い日本語音声認識(STT/ASR)モデル比較|Whisper・Qwen
IT企業名・SaaS略語を含む実音声で9つのASRモデルを比較。Whisper・Qwen3-ASR・Granite 4.0のIT用語認識精度を実測。
記事を読む →現役AIエンジニアが厳選:LLM最新情報をノイズなく速く掴む17サイト【2026年版】
LLM・生成AIの最新情報を速く・正確に・ノイズ少なく追うために、現役AIエンジニアが厳選した一次情報源17サイトを紹介。研究・論文・実装・OSS・コミュニティ別に整理し、RSS活用法まで解説します。
記事を読む →