【2026年版】IT用語に強い日本語音声認識(STT/ASR)モデル比較|Whisper・Qwen
本記事は、IT企業名・サービス名・略語を含む実際の音声データで9つのASRモデルを評価した一次ベンチマークです。汎用的な日本語音声認識ベンチとは異なり、「openclawやARRをちゃんと書き起こせるか」という実務目線で評価しています。
IT用語によらない汎用的なベンチマークは前回の記事をご覧ください。
日本語ASRベンチマーク(前回)*
結論:ITドメイン特化で選ぶなら
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| 総合バランス | whisper | CER・速度・安定性のバランス最良。英語固有名詞の保持も安定 |
| 文字精度重視 | qwen3-asr-1.7b | CER_EN 0.0589で全モデル最良。日本語本文の脱落が最も少ない |
| リアルタイム処理 | nvidia/parakeet | RTF最小(0.003)。速度は圧倒的 |
| 英語語彙の保持 | voxtral-mini | CER 0.1354。長文でも英語固有名詞の保持率が高い |
| 避けるべき用途 | kotoba-whisper / ibm/granite | 今回のITドメインではCERが高く、脱落・崩壊が目立つ |
実際に日本語音声入力を使うなら、Neosophieのプロダクト「Sonophie」もあります。Mac上で日本語音声入力・文字起こし・議事録をまとめて扱えます。
なぜ「ITドメイン特化」のベンチマークが必要なのか
一般的な日本語ASRベンチマーク(CommonVoice、ReazonSpeechコーパスなど)は日常会話や朗読音声を中心に評価しています。しかし実務で音声認識を使う場面、特にAI系・IT系の会議やポッドキャストには特有の語彙が頻出します。
たとえばこういう発話です。
「我々のGo to MarketはエンタープライズSMBをターゲットに、ARRで2000万を目指しつつ、LLMをコアにしたディストリビューション戦略で……」
この文に登場する Go to Market、ARR、LLM、ディストリビューション は汎用ASRが苦手とする語彙の典型例です。
- ARR(Annual Recurring Revenue)は音が「エーアールアール」で、モデルによっては「エアラリー」「エアラリス」に聞こえてしまう
- SIer(System Integrator)は読み方自体が曖昧で、「エスアイヤー」「エスアイアー」など複数の正解がある
- 英語サービス名(OpenAI、Anthropic、Sansan、DeepSeekなど)はカタカナと英字が混在し、モデルの学習データ分布に依存する
こうした「ITドメインの現実」に対してどのASRが通用するのかを評価したのが本ベンチマークです。
ベンチマーク設計
テストデータ
- 話者が全て異なる音声 15本 × 約30秒
- IT企業名(Anthropic、OpenAI、Sansan、DeepSeekなど)
- サービス名(openclawなど架空名含む)
- IT略語(ARR、LLM、GUI、DHCP、HTML、SIer)
- カタカナ外来語(ディストリビューション、インフラ)
- 製品名(Windows95、Mac Mini、PowerPoint、Excel、iPhone)
評価指標
| 指標 | 説明 |
|---|---|
| CER | Character Error Rate。文字単位の誤り率。数値が低いほど良い。日本語は分かち書きしないため、単語単位の誤り率より実態を反映しやすい |
| CER_EN | 英語トークンを日本語読みにノーマライズした後のCER |
| AvgTx(s) | 平均書き起こし処理時間(秒) |
| RTF | Real Time Factor。1秒の音声処理にかかる時間の比率。0.1未満が概ねリアルタイム水準 |
CER_ENノーマライズとは?
英語表記(OpenClaw)と日本語カタカナ表記(オープンクロー)を「同じもの」として扱う正規化処理です。ASRが英語を英字で書き出しても日本語で書き出しても、意味的に合っていれば正解とみなします。これにより「英語読みか日本語読みか」というスタイルの違いで評価が揺れるのを防ぎます。
ノーマライズの変換辞書の一部:
[
{ "src": "OpenClaw", "dst": ["オープンクロー"] },
{ "src": "Java", "dst": ["ジャバ", "ジャヴァ"] },
{ "src": "Ruby", "dst": ["ルビー"] },
{ "src": "SIer", "dst": ["エスアイヤー", "エスアイアー"] },
{ "src": "DHCP", "dst": ["ディーエイチシーピー"] },
{ "src": "ARR", "dst": ["エーアールアール"] }
]
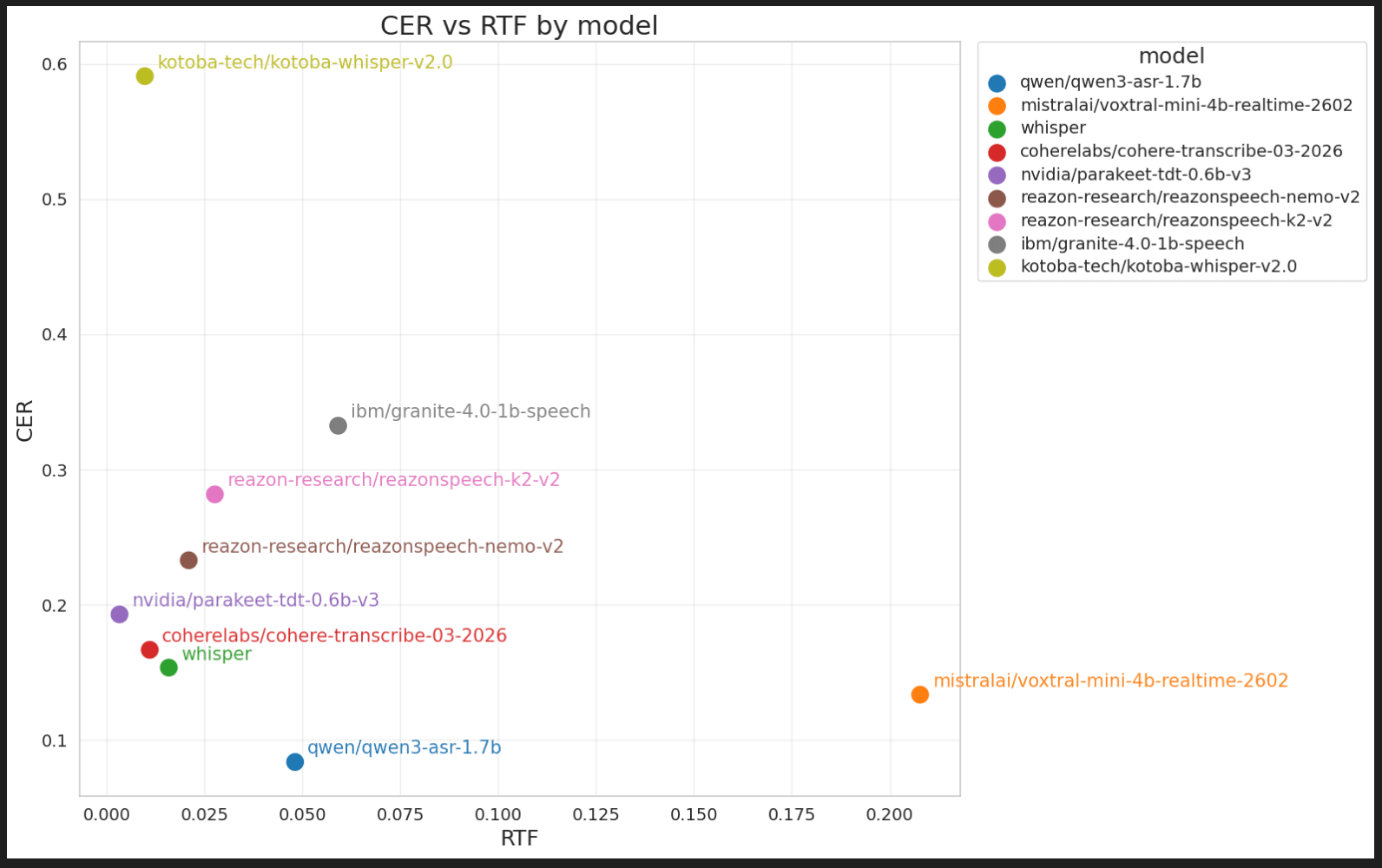
全モデル結果
通常評価(句読点除去後、CERランク順)
| ASR | CER↓ | CER_EN↓ | AvgTx(s)↓ | RTF↓ |
|---|---|---|---|---|
| qwen3-asr-1.7b | 0.0820 | 0.0589 | 1.43 | 0.048 |
| voxtral-mini-4b | 0.1354 | 0.1151 | 6.19 | 0.208 |
| whisper | 0.1565 | 0.1339 | 0.47 | 0.016 |
| cohere-transcribe | 0.1701 | 0.1566 | 0.33 | 0.011 |
| parakeet-tdt-0.6b | 0.1960 | 0.1696 | 0.10 | 0.003 |
| reazonspeech-nemo-v2 | 0.2332 | 0.2022 | 0.62 | 0.021 |
| granite-4.1-2b | 0.2724 | 0.2458 | 1.77 | 0.059 |
| reazonspeech-k2-v2 | 0.2855 | 0.2714 | 0.82 | 0.028 |
| granite-4.0-1b | 0.3542 | 0.3300 | 1.76 | 0.059 |
| kotoba-whisper-v2.0 | 0.6072 | 0.5859 | 0.29 | 0.010 |
CERで見るとqwen3-asr-1.7bが1位
qwen3-asr-1.7bはCER=0.0820、CER_EN=0.0589と他モデルに大差をつけて最良です。「文字レベルで正確に聞けている」という意味では今回のトップモデルです。ただし意味誤りのリスクが別途あるため、後述の詳細分析を必ず参照してください。
英語ノーマライズ後(CER_ENの改善幅)
| ASR | CER | CER_EN | 改善幅 |
|---|---|---|---|
| whisper | 0.1565 | 0.1339 | -0.0226 |
| voxtral-mini-4b | 0.1354 | 0.1151 | -0.0203 |
| cohere-transcribe | 0.1701 | 0.1566 | -0.0135 |
| parakeet-tdt-0.6b | 0.1960 | 0.1696 | -0.0264 |
| reazonspeech-nemo-v2 | 0.2332 | 0.2022 | -0.0310 |
| reazonspeech-k2-v2 | 0.2855 | 0.2714 | -0.0141 |
| granite-4.0-1b | 0.3542 | 0.3300 | -0.0242 |
| granite-4.1-2b | 0.2724 | 0.2458 | -0.0266 |
| qwen3-asr-1.7b | 0.0820 | 0.0589 | -0.0231 |
| kotoba-whisper-v2.0 | 0.6072 | 0.5859 | -0.0213 |
改善幅は全モデルで 0.013〜0.031 の範囲に収まっており、ノーマライズの恩恵は限定的です。このことは「そもそも音声認識の段階でどう書き出すか(英字かカタカナか)の揺れよりも、正しく聞き取れているかどうかが支配的」であることを示しています。
モデル別詳細分析
whisper(推奨:総合バランス)
スコア:CER 0.1565 / CER_EN 0.1339 / RTF 0.016
今回のITドメインベンチで最も総合バランスが取れていたのがwhisperです。Windows95、GUI、iPhone などの製品名は安定して書き起こせており、長文でも反復崩壊がありません。
弱点として、略語の「意味復元」は苦手な傾向があります。ARR を「エアラリー」と書き起こすケースが見られ、発音として似ているが意味的に正しくない変換が起きていました。とはいえ、これは他モデルにも共通する課題で、whisper はその発生頻度が最も低いグループです。
voxtral-mini-4b-realtime(英語語彙の保持率が高い)
スコア:CER 0.1354 / CER_EN 0.1151 / RTF 0.208
本文の自然さと情報保持のバランスでは voxtral-mini が whisper と並ぶ水準です。英語語彙の保持率が高く、長文でも途中で情報が脱落しにくいのが特徴です。
ただし RTF 0.208 は今回最も重いモデル です。平均処理時間が約6秒と、リアルタイム性が求められる用途には不向きです。バッチ書き起こしや精度優先の非同期処理には向いていますが、そのコストを把握した上で採用判断が必要です。
一部の固有名詞で局所的な崩れ(DeepSeek → DFC化など)が見られており、英語語彙を拾えてもノイズが混入するケースはあります。
qwen3-asr-1.7b(CER最良・文字精度トップ)
スコア:CER 0.0820 / CER_EN 0.0589 / RTF 0.048
最も特異なプロファイルを持つモデルです。CERは全モデル中最良(0.0820)、CER_ENに至っては0.0589と2位のvoxtral(0.1151)に大差をつけています。
これは「文字として正確に聞けている」ことを意味します。日本語テキストとして読んだときの自然な連続性は高く、出力長も原文に近い傾向があります。
意味誤りに注意
qwen3-asr-1.7bは音的に近いが意味が違う誤りが目立ちます。
SIer→SREARR→エアラリスSansan→サンソン
文字レベルでは近いが、IT知識として誤っている変換が出ます。そのまま議事録や字幕として使う場合は後処理でのLLMチェックを必ず挟むことを推奨します。
cohere-transcribe-03-2026(英語語彙保持・高速)
スコア:CER 0.1701 / CER_EN 0.1566 / RTF 0.011
PowerPoint、Excel、HTML などの英語製品名・タグ名はかなり安定しており、速度(RTF 0.011)も優秀です。
大きな弱点は 長文での前半脱落 です。全体を書き起こすのではなく、後半だけ綺麗に起こして前半を落とす傾向があります。また要約的に内容を縮める癖があるため、「全文を忠実に転写したい」用途には向いていません。議事録の要点抽出的な使い方なら許容できる挙動です。
nvidia/parakeet-tdt-0.6b-v3(速度最優先)
スコア:CER 0.1960 / CER_EN 0.1696 / RTF 0.003
RTF 0.003 は今回最速で、リアルタイム文字起こしや大量バッチ処理で最も有力な選択肢です。反復崩壊も少なく、出力の安定性は高いです。
ITドメインでの弱点は技術語彙の読み替えです。
Excel→x7HTML→hシメルARR系の崩れ
骨格としての日本語文は保ちますが、技術的な固有名詞の信頼性は低め。速度を優先した上で後段にLLM補正を挟む設計が現実的です。
reazonspeech-nemo-v2 / k2-v2
nemo-v2:CER 0.2332 / CER_EN 0.2022 k2-v2:CER 0.2855 / CER_EN 0.2714
いずれも日本語本文の骨格は保てています。ReazonSpeechシリーズは日本語汎用で定評がありますが、ITドメインでは略語崩れが出ます(HTML → h7 など)。
k2-v2 は平均出力長が短く、長文での省略・脱落傾向が顕著です。Go to Market を含む発話で前半を大きく脱落させる例がありました。
ibm/granite-4.0-1b-speech(安定性に課題)
スコア:CER 0.3542 / CER_EN 0.3300 / RTF 0.059
良いサンプルではそこそこ読めますが、長文での反復崩壊が目立ちます。「そうそうそう…」のようなループに入る例が見られ、品質の分散が今回最大です。ベンチマーク目的での再現性に不安があり、本番投入には追加評価が必要です。
kotoba-tech/kotoba-whisper-v2.0(今回の条件では厳しい)
スコア:CER 0.6072 / CER_EN 0.5859 / RTF 0.010
速度は速いですが(RTF 0.010)、ITドメインのこの条件では今回最低の品質でした。
- 15件中12件で出力長が原文の75%未満に縮小
- 「ロロカル…」「マママ…」のような反復崩壊が複数件
- 固有名詞の保持率が全モデル中最低
同じwhisperベースでも元のwhisperとは大きく結果が乖離しています。学習データや蒸留の設計がこのドメインと相性が悪い可能性があり、用途を選ぶモデルです。
実装上の示唆:ITドメインASRをどう組み込むか
パターン1:精度優先のパイプライン
音声入力
└─ whisper or voxtral-mini(書き起こし)
└─ LLMによる略語・固有名詞チェック(後処理)
└─ 最終テキスト出力
whisper 単体でも安定していますが、ARR・SIer などIT略語の意味誤りが残るため、後段でLLMによる文脈補正を挟むと実用精度が向上します。
パターン2:速度優先のパイプライン
音声入力
└─ parakeet(RTF 0.003 で書き起こし)
└─ 信頼スコアの低いトークンをLLMで補完
└─ 最終テキスト出力
parakeet は速いが技術語彙が弱いため、x7(Excel)や hシメル(HTML)のような崩れをLLMで補正するハイブリッドが現実的です。
パターン3:CER重視(文字媒体向け)
音声入力
└─ qwen3-asr-1.7b(CER_EN最良)
└─ SIer→SREなどの意味誤りをLLMでフラグ
└─ 字幕・テキスト出力
qwen3 は文字精度が高いですが意味誤りのリスクがあるため、IT用語辞書や文脈チェックとセットで使うことを推奨します。
まとめ:ITドメインASR選定の判断基準
速度を最優先 → parakeet-tdt-0.6b (RTF 0.003)
英語語彙の保持を最優先 → voxtral-mini or whisper
文字精度(CER)を最優先 → qwen3-asr-1.7b(意味チェック必須)
汎用バランスで迷ったら → whisper(CER 0.1565・安定性高)
長文・全文保持 → voxtral-mini(ただし遅い)
速度と精度のバランス → cohere-transcribe(ただし前半脱落に注意)
どのモデルも「完璧なITドメイン対応」ではなく、略語と固有名詞の処理は後段の補正設計とセットで考えることが前提です。特にARRやSIerのような「発音が曖昧な略語」はASR単体での正確な復元を期待しない方が現実的です。
FAQ
Q. 今回のベンチマークはどんなハードウェアで実行しましたか?
A. RTX 5090で実行しています。RTFの絶対値はGPU環境に依存するため、他環境では数値が変わります。ただし相対的な大小関係(parakeet が最速、voxtral が最重)は環境に関わらず概ね安定します。
Q. whisper のバージョン(large / medium / small)はどれですか?
A. 本ベンチでは whisper large v3 turbo を使用しています。バージョンによってスコアは大きく変わるため、追試時はバージョンを固定して比較することを推奨します。
Q. CER_EN ノーマライズの辞書はどこで入手できますか?
A. 今回は独自に作成した変換辞書を使用しています。SIer の「エスアイヤー / エスアイアー」のように複数読みがある語彙は全て列挙しています。辞書の公開については今後検討予定です。
Q. リアルタイム字幕生成ユースケースではどのモデルが最適ですか?
A. RTF 0.003 の parakeet が最も現実的です。技術語彙の崩れは残りますが、後段のLLM補正で緩和できます。voxtral-mini は RTF 0.208 でリアルタイムには不向きです。
Q. 日本語汎用ベンチ(CommonVoiceなど)と結果が異なるのはなぜですか?
A. 汎用ベンチは日常会話・朗読中心で、IT略語・英語混在・専門用語を含む発話はほぼ含まれません。モデルの汎用スコアと実務ITドメインスコアは相関しないことがあります。今回の kotoba-whisper の結果がその典型例です。
Q. qwen3-asr は今後 IT ドメインで改善が期待できますか?
A. CER が突出して良い点から、モデルの基礎能力は高いと評価できます。意味誤りの多くは IT 専門語彙の学習データ不足に起因すると推測されるため、ファインチューニングや後処理辞書との組み合わせで改善余地は大きいと考えています。
関連するブログ
この記事に近いテーマのブログをピックアップしています。
【2026年最新】日本語音声認識(ASR / STT)モデル比較:Whisper・Qwen3・Cohere・Graniteをベンチマーク
WhisperやQwen3-ASR、ReazonSpeech、Parakeetなど8モデルを同条件で比較。WER・速度・用途別お すすめをまとめました。
記事を読む →高精度の日本語音声認識モデルを無償公開
日本語ASRのCER最強モデルQwen3-ASR-1.7Bを固有名詞特化でファインチューニング。CERと固有名詞F1の両軸でWhisperを上回る最高水準を実現。Hugging Faceで無償公開中。macOSアプリSonophieでも利用可能。
記事を読む →WER・CERだけでは不十分?日本語音声認識を「名詞・固有名詞F1スコア」で再評価した結果
日本語音声認識は漢字や固有名詞の表記多く他言語に比べて難しい。そこで、WERやCERでは見えにくい「漢字・固有名詞の認識精度」を定量化するために、Sudachiによる形態素解析ベースのF1スコア評価を実装し、オープンソース音声認識モデル9種を再評価した一次ベンチマーク記事です。
記事を読む →