【2026年最新】日本語音声認識(ASR / STT)モデル比較:Whisper・Qwen3・Cohere・Graniteをベンチマーク
更新履歴
2026/0430 ibm-granite/granite-speech-4.1-2b の検証結果を追加しました。
2026/03/28 coherelabs/cohere-transcribe-03-2026 の検証結果を追加しました。
2026/03/23 ibm/granite-4.0-1b-speech の検証結果を追加しました。
この記事でわかること: 9種類の日本語音声認識(ASR)モデルを同一条件でベンチマークした一次データを公開。WER・CER・RTFで比較し、「どの用途にどのモデルが最適か」を実体験から解説します。
👉IT用語に強い日本語音声認識モデルのベンチマーク
👉最高水準の日本語音声認識モデルを無償公開
要約
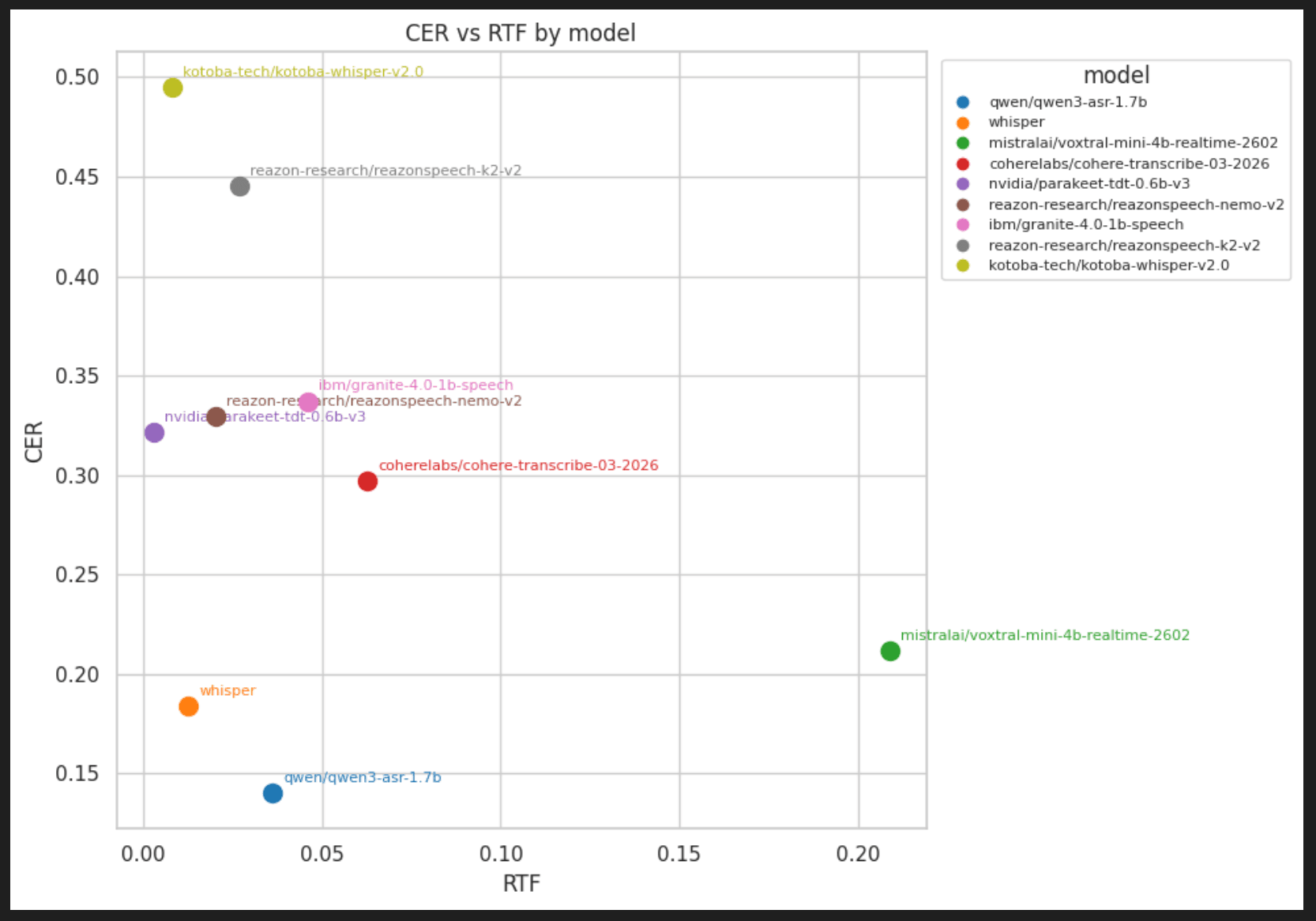
RTX5090を使って20本(計580秒・約10分)の自然会話音声を使い、最新の日本語むけASRモデルを評価しました。総合的な精度・安定性ではopenai/whisper-large-v3-turboとqwen/qwen3-asr-1.7bが頭一つ抜け出しています。 速度最優先ならnvidia/parakeet-tdt-0.6b-v3(RTF=0.002)、日本語特化のドメイン適応ならreazon-research/reazonspeech-espnet-v2が有力な選択肢です。
| モデル | WER↓ | CER↓ | RTF↓ | 総合評価 |
|---|---|---|---|---|
| qwen/qwen3-asr-1.7b | 0.185 | 0.140 | 0.036 | ⭐⭐⭐⭐⭐ |
| whisper | 0.218 | 0.184 | 0.013 | ⭐⭐⭐⭐⭐ |
| mistralai/voxtral-mini-4b-realtime-2602 | 0.239 | 0.212 | 0.209 | ⭐⭐⭐ |
| ibm-granite/granite-speech-4.1-2b | 0.281 | 0.262 | 0.051 | ⭐⭐⭐ |
| coherelabs/cohere-transcribe-03-2026 | 0.327 | 0.297 | 0.063 | ⭐⭐⭐ |
| nvidia/parakeet-tdt-0.6b-v3 | 0.344 | 0.321 | 0.003 | ⭐⭐⭐ |
| reazon-research/reazonspeech-nemo-v2 | 0.348 | 0.329 | 0.020 | ⭐⭐⭐ |
| ibm/granite-4.0-1b-speech | 0.378 | 0.337 | 0.046 | ⭐⭐ |
| reazon-research/reazonspeech-k2-v2 | 0.461 | 0.445 | 0.027 | ⭐⭐ |
| kotoba-tech/kotoba-whisper-v2.0 | 0.534 | 0.495 | 0.008 | ⭐ |
実際に日本語音声入力を使うなら、Neosophieのプロダクト「Sonophie」もあります。Mac上で日本語音声入力・文字起こし・議事録をまとめて扱えます。
テスト環境と評価データについて
ハードウェア・設定
GPU: RTX5090
temperature: 0.0
max_new_tokens: 512
language: ja
テストデータセット(20本・各29秒)
このベンチマークが表面的なまとめ記事と異なる最大の理由は、実際のメディア音声を使っているという点です。
- ニュース読み上げ: 標準的なアナウンサー発話
- エンタメ(お笑い・バラエティ): フィラー・笑い声・早口が混在
- ドラマ・アニメ: 感情的な発声、スラング(「てめぇ」「ババー!」等)
- ビジネス・リアリティショー: 複数話者の重なり
複数話者の重なりや笑い声のノイズを含むことで、実運用に近い難しいシナリオを再現しています。
指標の説明
WER(Word Error Rate:単語誤り率)
WER = (置換 + 削除 + 挿入) / 参照単語数
値が小さいほど精度が高い。日本語は英語と違ってスペースで単語が区切られないため、MeCab(形態素解析器)で分かち書きしてからWERを計算しています。また、句読点(、。!?)や記号はモデルごとに付け方が異なるため、評価前にすべて除去して公平な比較を実現しています。詳細は「再現方法」セクションをご覧ください。
CER(Character Error Rate:文字誤り率)
文字単位での誤り率。日本語評価ではWERより信頼性が高いとされます。今回の結果でもWERとCERの順位はほぼ一致しており、両指標の整合性が確認できました。
RTF(Real-Time Factor:リアルタイム係数)
RTF = 処理時間 / 音声の長さ
RTF < 1.0 でリアルタイム処理可能。RTF=0.002のparakeetは、29秒の音声を約0.06秒で処理する計算になります。
モデル別に何件一番いいWERを記録したのか。
qwenが他のモデルを圧倒して、20件中8件で一番低いWERを記録している。
| asr | num_best_wer | |
|---|---|---|
| 0 | qwen/qwen3-asr-1.7b | 8 |
| 1 | mistralai/voxtral-mini-4b-realtime-2602 | 3 |
| 2 | reazon-research/reazonspeech-espnet-v2 | 3 |
| 3 | whisper | 3 |
| 4 | ibm/granite-4.0-1b-speech | 1 |
| 5 | coherelabs/cohere-transcribe-03-2026 | 1 |
| 6 | reazon-research/reazonspeech-k2-v2 | 1 |
各モデルの詳細分析
🥇 qwen/qwen3-asr-1.7b — 最高精度(WER: 0.1899)
このモデルの最大の特徴は「補完能力」です。
単なる音の置き換えではなく、文章として成立するように文脈を補完します。息継ぎのタイミングに合わせて句読点が打たれており、まるで書き起こし記者が書いたような仕上がりです。
実際の出力例(具体的な差異):
- フィラー(「えー」「あの」)を適切に間引きつつ、重要な助詞は保持
- 20本中、WERが0.5を超えたのは1本のみ。それ以外は0.2以内と安定性が際立っています
注意点:
- ネットスラングや固有名詞で「空耳」(独自解釈)が発生することがある
- 平均処理時間0.99秒(RTF=0.034)と、whisperの約3倍の処理時間
🥈 openai/whisper-large-v3-turbo — 安定の汎用性(WER: 0.2099)
群を抜く文脈理解力が強みです。
ReazonSpeech系列が沈黙したり後半を切り捨てていた雑談パートを、ほぼ完璧に書き起こしました。
強み:
- フィラーを適宜間引きながら、助詞を補完して文章を成立させる
- 複数話者・ノイズ混在でも崩れにくい
弱点:Hallucination(幻覚)
Whisperには音声のない場所で存在しない文章を生成する「幻覚」現象があります。今回は参照に存在しない「私」という単語が末尾に付加されました。長時間音声での運用時は後処理で検知する仕組みが必要です。
reazon-research/reazonspeech-espnet-v2 — 日本語ドメイン適応(WER: 0.2342)
日本のメディア放送データで学習されており、「トー横」(東横の俗称) のような地名と俗称を文脈で切り分ける能力が実証されました。これはニュース・報道用途で大きなアドバンテージです。
感嘆符(!)・疑問符(?)を積極的に使用し、会話の勢いや感情を再現しようとする傾向があります。
弱点:
- RTF=0.589と最も遅い(29秒の音声に約17秒かかる)
- フィラーを積極的にカットするため、フィラー保持が必要な用途には不向き
mistralai/voxtral-mini-4b-realtime-2602 — 読みやすさ優先(WER: 0.2437)
音声の忠実な再現より「読みやすさ」を優先する設計が明確です。
具体例:
ぐらい→くらい(表記統一)っていうか→というのか(口語を書き言葉に変換)
字幕制作や議事録など、可読性が重要な用途に向いています。
1本のファイルでアラビア語のような文字列が突然出力されました。本番運用では言語検証のバリデーション処理が必須です。
nvidia/parakeet-tdt-0.6b-v3 — 超高速処理(RTF: 0.002)
RTF=0.002は今回のベンチマーク最速。 29秒の音声を約0.06秒で処理します。
TDT(Transducer with Dynamic Time Alignment)アーキテクチャの特性上、エネルギーの低い音声や重要度が低いと判断されたトークンをスキップします。この「積極的な省略」がWER=0.3465という精度に影響しています。
向いている用途:
- リアルタイムキャプションの下書き
- 大量音声ファイルの高速インデックス作成(精度より速度優先)
向いていない用途:
- 詳細な議事録、ドラマや会話の完全書き起こし
reazonspeech-nemo-v2 と k2-v2 の比較
両者とも同じReazonSpeechブランドですが、表記スタイルに明確な差があります。
| 比較項目 | nemo-v2 | k2-v2 |
|---|---|---|
| 数字表記 | 13歳(半角) | 十三歳(漢数字) |
| 英字 | gps(小文字) | GPS |
| 処理速度 | RTF=0.020 | RTF=0.026 |
| 省略傾向 | 後半が消える | 中間を省略(中抜き) |
nemo-v2は警察用語「マル暴(マルボウ)」を正確に漢字変換できるなど、専門用語への対応力も示しました。
ibm/granite-4.0-1b-speech — 二極化する精度(WER: 0.4058)
IBM Researchが開発した音声認識特化モデル。1Bパラメータのコンパクトな設計で、RTF=0.061と実用的な処理速度を持ちます。しかし、「クリアな音声に強く・ノイズ混在に極端に弱い」という二極化した挙動が今回の検証で明らかになりました。
良好なサンプルでの実力
ニュース読み上げやクリアなビジネス会話サンプルではCERが10%前後という非常に高い精度を示しました。これは上位モデルと遜色のないレベルです。
「クリアな音声に限定すれば」whisper・qwen3に迫る実力を持っており、ドメインが絞れる用途では有力な選択肢になり得ます。
課題:ハルシネーションとループ現象
ノイズ混在・複数話者サンプルではCERが70〜90%を超えるケースが多発しました。20本の平均をこれほど押し下げているのは、この「崩壊するサンプル」の存在が大きく影響しています。
今回観測された問題を具体的に分類します。
① ループ現象(Repetition Loop)
「…いいねいいねいいねいいね…」
「はいはいはいはいはいはいはい…」
Transformerベースモデルで発生しやすい現象で、無音区間・BGM・笑い声などの「非言語音」を無理に言語化しようとしてデコードがループに陥ることが原因として考えられます。Whisperでも知られる問題ですが、Graniteでは発生頻度が高く安定性に欠けます。
② 早期停止(Early Stopping)
正解テキストが十分な長さにもかかわらず認識結果が極端に短いケースが確認されました。複数話者の発話オーバーラップ、または音声切り替わりポイントでのVAD(音声区間検出)失敗により、モデルが「発話終了」と誤判定している可能性があります。
③ 固有名詞・漢字変換の誤り
| 正解 | Granite出力 | 備考 |
|---|---|---|
| マル暴 | 丸棒 | 音は合っているが漢字が誤り |
| 霜降り明星 | 下振り明星 | 音声的に近い誤変換 |
音韻レベルでの認識は成功しているケースでも、漢字変換フェーズで失敗するパターンが目立ちます。日本語固有名詞・俗語への対応はまだ発展途上と見られます。
④ フィラー周辺での不安定性
「えー」「まー」などのフィラー(言いよどみ)直後の重要な単語が欠落するケースが複数観測されました。フィラーを処理しようとした際に後続の認識コンテキストが乱れる、という挙動です。
kotoba-whisper-v2.0 — 今回の結果では最下位(WER: 0.5402)
ニュース原稿のような明瞭な音声には対応できますが、自然会話・感情音声・複数話者には課題が顕著でした。
特徴的な問題:
- 音声が不明瞭な際に同じフレーズを繰り返す
- フィラー(「えっと」「あの」「まー」)の直後の重要な単語が欠落する
- 音声の最初の部分が書き起こせないケースがある
モデル横断比較:ループ現象の発生傾向
今回の検証で特に注目すべきは、複数のモデルでループ(繰り返し)現象が観測された点です。
| モデル | ループ発生 | 対策の有効性 |
|---|---|---|
| whisper-large-v3-turbo | 稀(幻覚として末尾付加) | VAD前処理・no_speech_thresholdで軽減可 |
| granite-4.0-1b-speech | 頻発(BGM・笑い声で顕著) | 繰り返し検知の後処理が必須 |
| kotoba-whisper-v2.0 | 音声不明瞭時に発生 | — |
ループ現象はモデルアーキテクチャの問題ではなく、「非言語音(笑い声・BGM・息継ぎ)をどう扱うか」というデータ学習の問題に起因することが多いです。日本語のバラエティ・エンタメ音声は、こうした非言語音が多く含まれるため、特に発生しやすい環境と言えます。
用途別おすすめモデル
精度最優先(議事録・字幕)
→ qwen3-asr-1.7b または whisper-large-v3-turbo
日本語メディア特化(ニュース・報道)
→ reazonspeech-espnet-v2
速度最優先(リアルタイム・バッチ処理)
→ parakeet-tdt-0.6b-v3
可読性重視(書き言葉に変換したい)
→ voxtral-mini(ただし言語バリデーション必須)
クリアな音声限定・軽量モデルが必要
→ granite-4.0-1b-speech(ループ対策の後処理と組み合わせて)
避けるべき用途があるモデル
→ kotoba-whisper-v2.0(自然会話)
→ voxtral-mini(言語バリデーション未実装の場合)
→ granite-4.0-1b-speech(バラエティ・感情音声・複数話者)
再現方法:WER評価パイプラインの全体像
このベンチマークで最も重要なのは「どうやってWERを公平に計算するか」という設計です。特に日本語ASRのWER計算には独自の工夫が必要で、単純に jiwer.wer(ref, hyp) を呼ぶだけでは正確な評価になりません。
Step 1:テキスト正規化(句読点・記号・スペースの除去)
ASRモデルによって句読点の付け方が大きく異なります。例えばreazonspeech-espnet-v2は ! や ? を積極的に挿入しますが、参照テキスト(アノテーション)にはそれらがない場合があります。句読点の有無でWERが不公平に変動しないよう、評価前にすべて除去します。
import unicodedata
def normalize_text(text: str) -> str:
# NFKC正規化:全角英数→半角、異体字の統一など
text = unicodedata.normalize("NFKC", text)
chars: list[str] = []
for ch in text:
cat = unicodedata.category(ch)
if cat.startswith("Z"): # スペース・イデオグラフィックスペース等の区切り文字
continue
if cat.startswith("P"): # 句読点(、。!?「」など)
continue
if cat.startswith("S"): # 記号(¥、©など)
continue
chars.append(ch)
return "".join(chars).strip()
この正規化により、以下のような「表記揺れ」による誤評価を防いでいます。
| 処理 | 変換例 |
|---|---|
| NFKC正規化 | 13歳 → 13歳、km → km |
| 句読点除去 | 行って、叫んで。 → 行って叫んで |
| スペース除去 | 東京 都 → 東京都 |
Step 2:MeCabによる日本語分かち書き(WER専用)
日本語はスペースで単語が区切られないため、英語と同じ方法でWERを計算できません。スペース分割ではなくMeCabで形態素解析(分かち書き)してからWERを計算しています。
import MeCab
_MECAB_TAGGER = None
def _get_mecab_tagger():
global _MECAB_TAGGER
if _MECAB_TAGGER is None:
# -Owakati:分かち書きモードで出力
_MECAB_TAGGER = MeCab.Tagger("-Owakati")
return _MECAB_TAGGER
def _contains_japanese(text: str) -> bool:
for ch in text:
code = ord(ch)
if (
0x3040 <= code <= 0x30FF # ひらがな・カタカナ
or 0x4E00 <= code <= 0x9FFF # CJK統合漢字
or 0x3400 <= code <= 0x4DBF # CJK拡張A
):
return True
return False
def tokenize_for_wer(text: str) -> list[str]:
# すでにスペース区切りなら分割(英語等)
if " " in text:
return [tok for tok in text.split(" ") if tok]
# 日本語が含まれていればMeCabで分かち書き
if _contains_japanese(text):
tagger = _get_mecab_tagger()
parsed = str(tagger.parse(text) or "").strip()
return [w for w in parsed.split() if w]
# その他(純粋な英数字等)は文字単位
return [ch for ch in text if not ch.isspace()]
なぜMeCabが必要か? 例として「行ってきました」という単語がある場合、単純な文字分割だとすべての文字が独立したトークンになりますが、MeCabなら 行っ / て / き / まし / た と形態素単位に分割されます。これにより「削除」「挿入」の数が実際の誤りに近い値になります。
Step 3:CER計算(文字単位)
CERはシンプルに文字単位で分割します。スペースのみ除外します。
def tokenize_for_cer(text: str) -> list[str]:
return [ch for ch in text if not ch.isspace()]
Step 4:jiwer でエラーレート計算
トークン列をスペース結合した文字列としてjiwerに渡し、置換・削除・挿入の数を取得します。
import jiwer
def compute_error_rate(ref: str, hyp: str, mode: str) -> tuple[float, int, int]:
ref_n = normalize_text(ref)
hyp_n = normalize_text(hyp)
if mode == "wer":
ref_tokens = tokenize_for_wer(ref_n)
hyp_tokens = tokenize_for_wer(hyp_n)
elif mode == "cer":
ref_tokens = tokenize_for_cer(ref_n)
hyp_tokens = tokenize_for_cer(hyp_n)
# jiwer はスペース区切りの文字列として受け取る
out = jiwer.process_words(
" ".join(ref_tokens),
" ".join(hyp_tokens)
)
err = int(out.substitutions + out.deletions + out.insertions)
total = int(out.hits + out.substitutions + out.deletions)
return (err / max(total, 1)), err, total
最終的なWER・CERは、20サンプル全体の誤り数と参照トークン数を集計したコーパス全体の集計値として算出しています(サンプルごとのWERを平均するのではなく、全体での Σerr / Σtotal を使用)。これにより短いサンプルの影響を抑えた公平な評価になります。
Step 5:RTF(リアルタイム係数)の計測
各ASRモデルはサブプロセスとして起動し、transcribe_elapsed_sec(推論時間)とaudio_duration_sec(音声の長さ)をJSONで返します。RTFはその比です。
# 各モデルのtranscribe.pyが返すJSONの形式
{
"text": "書き起こされたテキスト",
"transcribe_elapsed_sec": 0.34, # 推論にかかった秒数
"audio_duration_sec": 29.0, # 音声の長さ(秒)
"rtf": 0.012 # transcribe_elapsed / audio_duration
}
# コーパス全体のRTF = Σtranscribe_elapsed / Σaudio_duration
rtf = transcribe_elapsed_sum / audio_duration_sum
依存ライブラリ
jiwer # WER/CER計算
MeCab # 日本語形態素解析(分かち書き)
unicodedata # テキスト正規化(Python標準ライブラリ)
MeCabのインストール(Ubuntu系):
sudo apt-get install mecab libmecab-dev mecab-ipadic-utf8
pip install mecab-python3 jiwer
FAQ(よくある質問)
Q1. 日本語ASRで一番精度が高いモデルは何ですか?
今回のベンチマークでは qwen/qwen3-asr-1.7b(WER=0.1899)が最高精度でした。ただし自然会話・ノイズ混在環境での安定性は whisper も同等で、用途によって使い分けが重要です。
Q2. WERとCERどちらを見ればいいですか?
日本語の場合、分かち書きの曖昧さからWERは過剰に悪化することがあります。今回はMeCabで形態素解析してから計算しているため、単純な文字分割よりは信頼性が高いですが、それでもCERをメインの評価指標にすることを推奨します。今回の結果でも両者の順位はほぼ一致していました。
Q3. リアルタイム文字起こしに向いているモデルは?
RTF < 0.1が実用的な目安です。今回の結果では parakeet-tdt-0.6b-v3(RTF=0.002)、whisper(RTF=0.012)、nemo-v2(RTF=0.020)、granite-4.0-1b-speech(RTF=0.061)が該当します。ただし精度とのトレードオフを考慮してください。Graniteはリアルタイム処理に対応できる速度ですが、ノイズ環境での安定性が課題です。
Q4. フィラー(えー・あのー)を保持したい場合は?
qwen3-asr-1.7b や whisper は適宜間引きますが、比較的忠実です。reazonspeech-espnet-v2 は積極的にカットするため不向きです。
Q5. 複数話者が混在する音声に強いモデルは?
今回のテストでは whisper と qwen3-asr-1.7b が複数話者・ノイズ混在環境でも安定した精度を維持しました。ReazonSpeech系列は複数話者が重なると後半を切り捨てる傾向があります。Granite・kotoba-whisperは複数話者環境には不向きです。
Q6. Whisperの幻覚(Hallucination)はどう対策すればいいですか?
①無音区間の事前VAD(音声区間検出)処理、②繰り返しパターンの後処理検知、③no_speech_thresholdパラメータの調整、が有効です。長時間音声での運用時は特に注意が必要です。
Q7. voxtral-miniがアラビア語を出力したのはなぜですか?
詳細な原因は不明ですが、多言語モデル特有の言語混在問題と推測されます。本番環境では出力言語の自動バリデーションを実装することを強く推奨します。
Q8. granite-4.0-1b-speechはなぜ精度が二極化しているのですか?
Graniteは英語中心のデータで学習されたモデルをベースに音声認識能力を付与した設計と考えられます。標準的な日本語(ニュース・アナウンス)には対応できますが、笑い声・BGM・複数話者の重なりといった「非言語音が多い環境」では、デコードがループに陥りやすいと推測されます。これはモデルの学習データにそうした困難なケースが十分に含まれていない可能性を示しています。
Q9. ループ現象を後処理で除去するとWERは改善しますか?
ループ部分を除去するとCER・WERは改善しますが、「本来認識すべきだった音声部分」の情報は失われます。ループ除去後でも早期停止(発話の途中で止まる)問題は残るため、根本的な解決にはなりません。後処理はあくまで「異常出力の無害化」であり、精度改善ではないと理解した上で使用してください。
Q10. このベンチマークはどのくらい信頼できますか?
20本のテストデータはジャンルを分散させていますが、サンプル数としては限定的です。特定ドメイン(医療・法律など)での運用では、そのドメインのデータで追加評価することを推奨します。
まとめ
9モデルを同一条件でベンチマークした結果をまとめると:
- 精度・安定性のバランス:
qwen3-asr-1.7b>whisper - 日本語メディア特化:
reazonspeech-espnet-v2 - 速度重視:
parakeet-tdt-0.6b-v3 - クリアな音声・軽量モデル:
granite-4.0-1b-speech(ループ後処理必須) - 避けるべき用途があるモデル:
kotoba-whisper-v2.0(自然会話)、voxtral-mini(言語バリデーション未実装の場合)、granite-4.0-1b-speech(ノイズ混在・複数話者環境)
音声認識はモデル選定だけでなく、前処理(ノイズ除去・話者分離)と後処理(幻覚検知・ループ除去・言語バリデーション)の組み合わせで大きく精度が変わります。本記事のデータを参考に、用途に合わせた最適なパイプラインを構築してください。
関連するブログ
この記事に近いテーマのブログをピックアップしています。
【2026年版】IT用語に強い日本語音声認識(STT/ASR)モデル比較|Whisper・Qwen
IT企業名・SaaS略語を含む実音声で9つのASRモデルを比較。Whisper・Qwen3-ASR・Granite 4.0のIT用語認識精度を実測。
記事を読む →高精度の日本語音声認識モデルを無償公開
日本語ASRのCER最強モデルQwen3-ASR-1.7Bを固有名詞特化でファインチューニング。CERと固有名詞F1の両軸でWhisperを上回る最高水準を実現。Hugging Faceで無償公開中。macOSアプリSonophieでも利用可能。
記事を読む →WER・CERだけでは不十分?日本語音声認識を「名詞・固有名詞F1スコア」で再評価した結果
日本語音声認識は漢字や固有名詞の表記多く他言語に比べて難しい。そこで、WERやCERでは見えにくい「漢字・固有名詞の認識精度」を定量化するために、Sudachiによる形態素解析ベースのF1スコア評価を実装し、オープンソース音声認識モデル9種を再評価した一次ベンチマーク記事です。
記事を読む →